
The GLOBALISE project is an ambitious initiative to revolutionise research into the archives of the Dutch East India Company (VOC). Focusing particularly on the Overgekomen Brieven en Papieren (OBP) series, we aim to provide unprecedented access to documents that illuminate the VOC’s operations and the history of societies of early modern Asia, Africa, and Australia. These archives offer a unique perspective on the VOC’s complex role in history, not only as a trading giant but also as a colonial power, which included the perpetuation of practices like slavery. Our goal is to facilitate the creation of new, diverse, and representative histories by making these invaluable resources accessible and researchable.
In the short (Dutch-language) video below, project leader Matthias van Rossum explains how we do this and discusses the impact on research with Cátia Antunes, Professor of History of Global Economic Networks at Leiden University.

Video credits: Notion Film & Animation
Project Stages
In building an advanced research infrastructure around the approximately 5 million scans of the OBP, provided by the Dutch National Archives, our project is structured into the following key stages, each focusing on processing and enriching this invaluable archive series:
Text Recognition
Utilising the state-of-the-art Handwritten Text Recognition (HTR) software Loghi, developed at the Digital Infrastructure department of the KNAW Humanities Cluster, we have processed the nearly 5 million scans from the Dutch National Archives. Using models trained on a substantial ‘ground truth’ collection, partly created by our team, Loghi identifies text regions and transcribes their content, rendering these historic documents searchable and accessible. The transcriptions are available in a prototype viewer and for download on our Dataverse.



Entity and Event Recognition
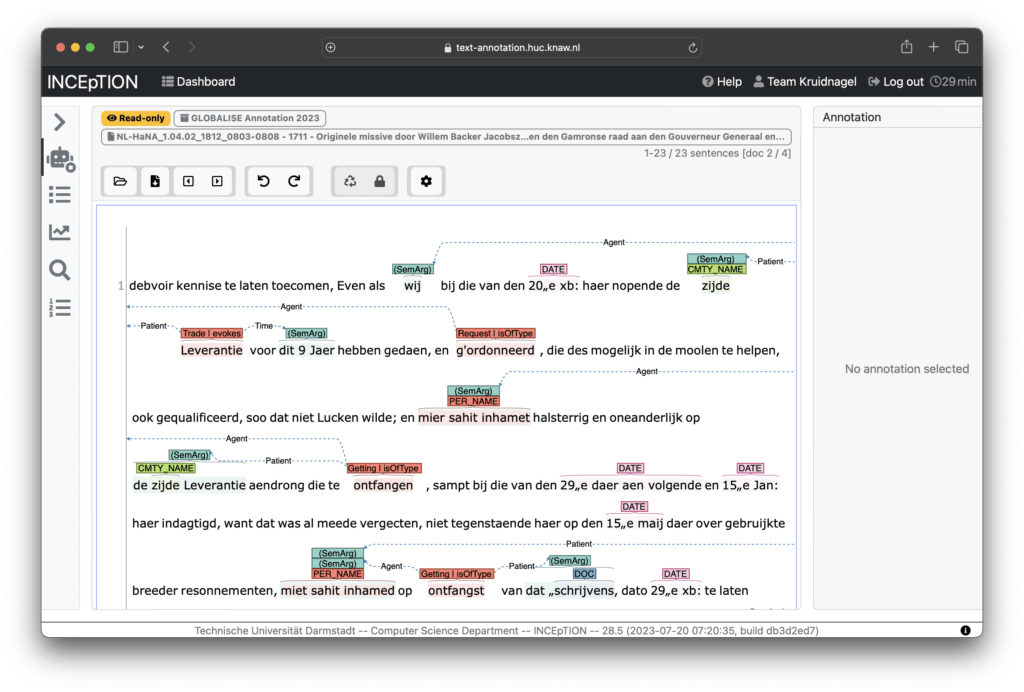
Our team of historians and computational linguists works on manually tagging entities and events in a sample of documents, using the INCEpTION tool. This meticulous process underpins the training of language models to automatically recognise and extract similar data from the entire corpus. The event annotation and extraction is especially challenging, as is explained in this blog post.
Reference Data Creation and Contextualisation

Alongside, historians are assembling and structuring information from secondary literature and source publications. This blog post on our polities dataset describes this process in more detail. We are also working on datasets about persons, places, and weights and measures. The reference data creation also involves creating thesauri with definitions of various concepts found in the source documents. We tell about our effort to define hundreds of textiles in this blog post. The reference data collected is crucial for contextualising the entities and events identified in the previous step, adding depth and nuance to the overall understanding of the archival content.
Development of an Advanced Research Platform
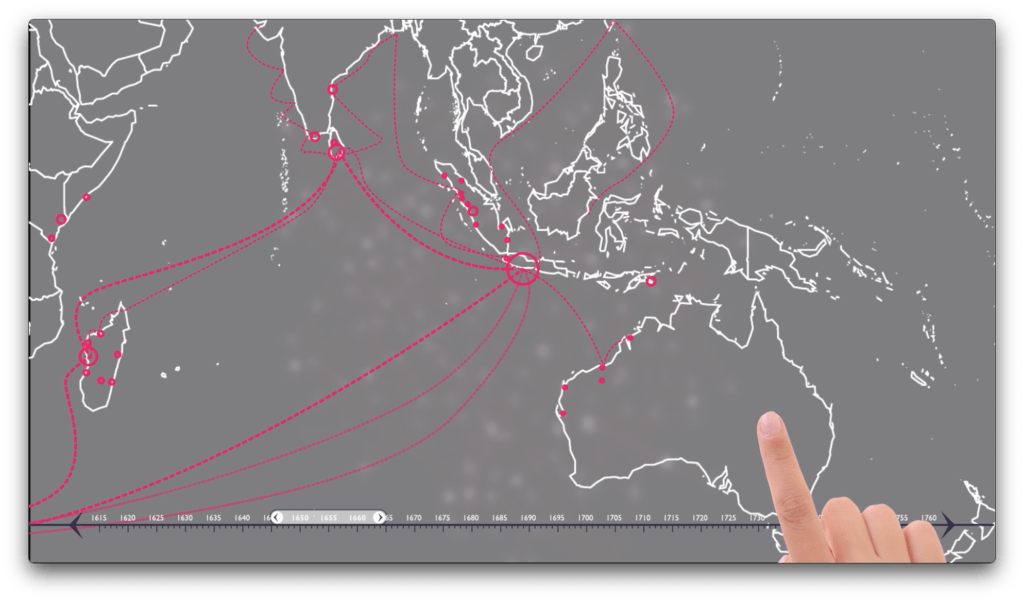
We are developing an advanced research platform that provides both standard and AI-powered text searches, along with access to data organised by our bespoke GLOBALISE ontology, currently under development. This ontology structures entity and event annotations as well as reference data, enabling users to explore complex relationships between various entities and events for in-depth research queries. We actively engage with our user panel for feedback on our platform development ideas, as detailed in this blog post.
Interactive User Engagement
GLOBALISE encourages active participation from users and citizen scientists. You can participate in our events, such as workshops and datasprints, or sign up as a guest researcher. Once the platform is live (expected in autumn 2025), users will be able to interact with the material by adding their own annotations and sharing these within the community. All annotations’ provenance is transparent, ensuring clarity on the origins, whether they are from the GLOBALISE team, AI language models, or users.
Research Impact
The GLOBALISE infrastructure will empower researchers to tackle new and complex research questions. Take, for instance, the seventeenth-century sugar boom in Taiwan: while the industry’s growth is linked to the influx of Chinese planters and migrants, the intricacies of labour relations on the plantations, including the use of slave labour reported by VOC officials, remain less explored. Could Chinese migrants and enslaved workers from other Asian regions have coexisted in the sugar industry? GLOBALISE enables in-depth investigation into these aspects by facilitating queries on sugar production development, migration patterns, and slave imports. Such research will offer significant insights into the broader implications of plantation societies, slave labour regimes, and the enduring impact of colonialism.
The creation of the GLOBALISE research facility is not just about developing digital infrastructure; it represents a significant contribution to digital humanities and historiography. By democratising access to these archives and enabling nuanced interpretations, we aim to challenge traditional narratives and provide new insights into the complex history of colonialism and its global impact.